У нас в мае будет экзамен по истории Казахстана (в прошлом году был экзамен по Природоведению)
В прошлом году я писал ответы к экзамену у себя на форуме, но с телефона читать их было сложно поэтому я подумал и в этот раз решил попробовать сделать приложение справочник с ответами к экзамену и опубликовать его у себя на Google Play чтобы все могли им пользоваться.
Как это лучше сделать?
Полная версия этой страницы: Как сделать приложение справочник на Андроид
t800
во-первых не понимаю - а почему нельзя тупо выложить какой-нибудь pdf, fb2 или подобное, а уж программ для чтения этих форматов - предостаточно.
Ну а если писать программу - я бы написал на Delphi, я сейчас именно кроссплатформенным программированием на делфи и занимаюсь - не так это сложно. Нужно просто вместо VCL немного познакомиться с системной библиотекой FireMonkey.
В Делфи 10 Сиэтл много предзаготовок.
Вот так выглядит, например, мой проект (предзаготовка - страница с вкладками).
Нажмите для просмотра прикрепленного файла
во-первых не понимаю - а почему нельзя тупо выложить какой-нибудь pdf, fb2 или подобное, а уж программ для чтения этих форматов - предостаточно.
Ну а если писать программу - я бы написал на Delphi, я сейчас именно кроссплатформенным программированием на делфи и занимаюсь - не так это сложно. Нужно просто вместо VCL немного познакомиться с системной библиотекой FireMonkey.
В Делфи 10 Сиэтл много предзаготовок.
Вот так выглядит, например, мой проект (предзаготовка - страница с вкладками).
Нажмите для просмотра прикрепленного файла
Для Delphi XE 10 Сиэтл. Взять listbox (listview), в его итемы загружать вопросы, по клику - ответы. Не забыть про searchbox для поиска.
hippocamus, и как тебе эта обезьяна?
hippocamus, и как тебе эта обезьяна?
Цитата(ivyl @ 23 Apr 2017, 00:40) 
hippocamus, и как тебе эта обезьяна?
Понтовая, а на поверку - слабоватая (попробуй, например, получить имя исполняемого файла!), но работать можно. В Delphi XE компонент интернет-браузера специализирован только под Android и iOS - а в Сиэтле - работает уже и под винду 32/64.Под винду всё же предпочитаю VCL.
(И очень хорошее достоинство этой Огнезьяны, как я её называю - она не пытается монополизировать ресурсы и отчасти совместима с VCL - при компиляции выдаётся warning о дублировании ресурсов (курсоров, например) - но не более - всё работает.)
Точно, в Сиэтле убрали приставку "XE". Меня больше раздражает, чем радует. Начиная с измененных свойств компонентов, заканчивая размером исполняемого файла.
ivyl
Размеры - да, впечатляют. Особенно под Андрюху - там около 20 метров чуть ли не за ХеллоуВорд берут... Но от дальнейшего роста приложения потом мало что изменяется. То есть - львиная доля - системные библиотеки.
Размеры - да, впечатляют. Особенно под Андрюху - там около 20 метров чуть ли не за ХеллоуВорд берут... Но от дальнейшего роста приложения потом мало что изменяется. То есть - львиная доля - системные библиотеки.
Цитата(hippocamus @ 23 Apr 2017, 03:24)
t800
во-первых не понимаю - а почему нельзя тупо выложить какой-нибудь pdf, fb2 или подобное, а уж программ для чтения этих форматов - предостаточно.
во-первых не понимаю - а почему нельзя тупо выложить какой-нибудь pdf, fb2 или подобное, а уж программ для чтения этих форматов - предостаточно.
Ну на Google Play только приложения можно выкладывать.
Цитата(hippocamus @ 23 Apr 2017, 03:24)
Ну а если писать программу - я бы написал на Delphi, я сейчас именно кроссплатформенным программированием на делфи и занимаюсь - не так это сложно. Нужно просто вместо VCL немного познакомиться с системной библиотекой FireMonkey.
В Делфи 10 Сиэтл много предзаготовок.
Вот так выглядит, например, мой проект (предзаготовка - страница с вкладками).
Нажмите для просмотра прикрепленного файла
В Делфи 10 Сиэтл много предзаготовок.
Вот так выглядит, например, мой проект (предзаготовка - страница с вкладками).
Нажмите для просмотра прикрепленного файла
Дельфи 10 это вот эта? См. http://maintracker.org/forum/viewtopic.php?t=5332874
Хммм.. А что-нибудь для Linux или Windows XP нету? И чтобы памяти так много не требовала (у меня в Ubuntu cтоит 1.5Гб) в Windows XP в VirtualBox
(750Mb)
Какие дельфи под андроид, люди. Есть же android studio и ненавистная java.
А по факту, для экзамена проще ответы загнать в word документ и сохранить как pdf. Ответы искать обычным поиском. 4 года способ не подводил.
А по факту, для экзамена проще ответы загнать в word документ и сохранить как pdf. Ответы искать обычным поиском. 4 года способ не подводил.
Цитата(SaintDark @ 23 Apr 2017, 09:22)
А по факту, для экзамена проще ответы загнать в word документ и сохранить как pdf. Ответы искать обычным поиском. 4 года способ не подводил.
Ну мне то и ответов на форуме хватит. Просто я хочу чтобы ответы были как справочник и чтобы можно было на Google Play выложить.
И это не для себя (я могу и на форуме всегла зайти) а чтобы все могли пользоваться.
PS Ну наверно можно и PDF сделать но так чтобы он был как приложение и чтобы его можно было на Google Play опубликовать
Так ну я вот нагуглил исходники вот этого PDF viewer
https://play.google.com/store/apps/details?...ample&hl=ru
https://github.com/barteksc/AndroidPdfViewer
И наверное можно передалть чтобы программа сразу мой файл с ответами открывала, но
какой то очень простой ни поиска нету ни кнопок.
А как-нибудь покрасивей сделать? Чтобы программа с кнопками была и с поиском?
Так нагуглил open-source библиотеку для epub файлов ИМХО покрасивей чем которая для PDF
См. https://github.com/psiegman/epublib
См. https://github.com/psiegman/epublib
Цитата(t800 @ 23 Apr 2017, 15:10)
А как-нибудь покрасивей сделать? Чтобы программа с кнопками была и с поиском?
Если так, то проще не изобретать велосипед с другими языками программирования и использовать java, которая предназначена именно для разработки под android. Благо, самоучителей по android разработке вагон
Цитата(t800 @ 23 Apr 2017, 06:17)
Хммм.. А что-нибудь для Linux или Windows XP нету? И чтобы памяти так много не требовала (у меня в Ubuntu cтоит 1.5Гб) в Windows XP в VirtualBox
(750Mb)
Начиная с Delphi XE3 среда требует уже минимум висту и гектар памяти. А разработка под андроид поддерживается только с XE5 (то есть - последние версии - XE5, XE6, 10 Seatle, 10.1 Berlin (последний под 6-й андроид)).(750Mb)
А почему не поставить простенькую Win7Starter на отдельный раздел?
Цитата(hippocamus @ 23 Apr 2017, 20:26)
Цитата(t800 @ 23 Apr 2017, 06:17)
Хммм.. А что-нибудь для Linux или Windows XP нету? И чтобы памяти так много не требовала (у меня в Ubuntu cтоит 1.5Гб) в Windows XP в VirtualBox
(750Mb)
Начиная с Delphi XE3 среда требует уже минимум висту и гектар памяти. А разработка под андроид поддерживается только с XE5 (то есть - последние версии - XE5, XE6, 10 Seatle, 10.1 Berlin (последний под 6-й андроид)).(750Mb)
А почему не поставить простенькую Win7Starter на отдельный раздел?
Ну не знаю. Как-то не хочется жесткий диск вообще трогоать (он у меня один) и на нем система стоит, поэтому Windows XP у меня в VirtualBox, туда же можно и Windows7 поставить и Windows8, но они тормозят очень сильно потому что больше 1Гига ОЗУ я им дать же не могу.
Ставить виндовс рядом с линуксом, чтобы поставить на него дельфи, чтобы кодить на нём под линукс (а андроид это линукс) - это идиотизм, хочу заметить.
Я тут нагуглил что многие делают приложения для Андроид просто из своих сайтов, т.е. просто копипуют сайт целиком в приложение и все,
тогда я поставил Android Studio для Linux и скачал вот эти исходники
https://github.com/tscolari/android-webview-sample-app
Потом поменял в исходниках адрес страницы на адрес своего сайта, откомпилировал и у меня получилось вот так:
тогда я поставил Android Studio для Linux и скачал вот эти исходники
https://github.com/tscolari/android-webview-sample-app
Потом поменял в исходниках адрес страницы на адрес своего сайта, откомпилировал и у меня получилось вот так:
С таким же успехом можно дать ссылку на свой сайт. У всех есть браузер в смартфоне. Более того, тогда это будет уже не только Андройд, но целая мультиплатформа .gif)
Цитата(Seiffear @ 25 Apr 2017, 20:06)
С таким же успехом можно дать ссылку на свой сайт. У всех есть браузер в смартфоне. Более того, тогда это будет уже не только Андройд, но целая мультиплатформа 
Ну вообще-то я хочу сделать приложение чтоб оно могло работать без интернета, потому интернет он может быть медленный, а во-вторых,
если очень много сразу на сайт зайдут он будет открываться очень медленно.
Вот сделал иконку для приложения

Вот сделал главную заставку для программы:

Оказывается чтобы засунуть сайт в приложение надо сделать так чтобы сайт был на чистом HTML и чтобы у каждого ответ лежал в своей HTML файлике 1.html , 2.html и т.д. до 51.html потому что вопросов к экзамену 51 и , кстати, то же самое должно быть с картинками которые в ответах, а я ответы 2 недели писал постами в теме у себя на форуме который на php и mysql cделан и когдя я представил сколько надо времени чтобы по новому переделать все ответы чтобы они были в HTML файлики у меня пропало все желание это делать. Но тут, в пятницу двадцать восьмого, учительна по истории вызлала меня и Мадияра, и дала задание: Мадияру - написать ответы на вопросы в тетради, мне - тоже самое, но разницей, чтобы я распечатал ответы. И всё это ей нужно ко вторнику. А это завтра. А так как бумаги у меня нет (а там надо распечатать 200 листов) то я напряг все силы, чтобы все-таки разобратся с программой, но остался вопрос как быть с HTML файликам. И тут я вспомнил про парсер который я делал для Дяди Степы и решил попорбовать спарсить свои посты с ответами так чтобы они записали в отдельные HTML файлики и с картинками.
Тогда я откыл свой старый скрипт и отредактировал его вот так:
Запустил его и через 3 минуты он создал мне в папке hystory 51 файлик html c отдельными ответами, а так же закачал и переменовал и в ставил в эти файлики 51 картинку с новыми именами.
Тогда я откыл свой старый скрипт и отредактировал его вот так:
Код
<?php
echo '<html xml:lang="ru-ru" lang="ru-ru" >';
echo '<head><meta http-equiv="content-type" content="text/html; charset=utf-8" /></head>';
set_time_limit(0); // это для того чтобы скрипт не отвалился через 30 секунд
//подгружаем библиотеку
require_once 'library/simplehtmldom.php';
//создаём новый объект
$html = new simple_html_dom();
//загружаем в него данные
$html = file_get_html('http://wiki.kvkozyrev.org/forum/viewtopic.php?f=26&t=193');
$i = 0;
$path = './history/';
$header = '<html xml:lang="ru-ru" lang="ru-ru" ><head><meta http-equiv="content-type" content="text/html; charset=utf-8" /></head>';
$style = '<style type="text/css">.content{text-align: justify} .t800{max-width:600px;} </style>';
foreach($html->find('div[class="postbody"]') as $postbody)
{
$h3 = $postbody->find('h3',0);
echo $h3->plaintext . '<br/>';
$content = $postbody->find('div[class=content]',0);
//echo $content . '<br/>';
$html2 = str_get_html($content);
$img = $html2->find('img[alt!=tablica.png]',0);
$img->outertext = '';
echo $html2->innertext;
// Создаем и пишем в HTML файл
$fp = fopen($path .$i . ".html", "w"); // Открываем файл в режиме записи
fwrite($fp,$header);
fwrite($fp,$style);
fwrite($fp,$html2->innertext);
//Конец записм в HTML файл
$newimg = $content->find('img[alt!=tablica.png]',0);
if ($newimg <> '' & $i < 52)
{
echo '<br/>Новый Имидж<br/>'. $newimg . '<br/>Конец нового имиджа<br/>';
echo '<br/><br/>I =' . $i . '<br/><br/>';
$url_img = $newimg->src;
echo '<br/>ВЫВОДИМ HREF: ' . $url_img;
$img_path = $path . $i . '.jpg';
grab_image($url_img,$img_path);
$img_html = '<br><img class="t800" src="'. $i . '.jpg" width="100%" height="auto" ><br>';
fwrite($fp,$img_html);
}
fclose($fp); //Закрытие файла
$i++;
}
//освобождаем ресурсы
$html->clear();
unset($html);
// Это функция grub_image() че картинки скачивает сurl-ом и сохраняет (взята из комментариев на Stack Overflow)
// ЗЫ сurl-ом потому что curl-ом быстрее скачивается
function grab_image($url,$saveto){
$ch = curl_init ($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_BINARYTRANSFER,1);
$raw=curl_exec($ch);
curl_close ($ch);
if(file_exists($saveto)){
unlink($saveto);
}
$fp = fopen($saveto,'x');
fwrite($fp, $raw);
fclose($fp);
}
?>
echo '<html xml:lang="ru-ru" lang="ru-ru" >';
echo '<head><meta http-equiv="content-type" content="text/html; charset=utf-8" /></head>';
set_time_limit(0); // это для того чтобы скрипт не отвалился через 30 секунд
//подгружаем библиотеку
require_once 'library/simplehtmldom.php';
//создаём новый объект
$html = new simple_html_dom();
//загружаем в него данные
$html = file_get_html('http://wiki.kvkozyrev.org/forum/viewtopic.php?f=26&t=193');
$i = 0;
$path = './history/';
$header = '<html xml:lang="ru-ru" lang="ru-ru" ><head><meta http-equiv="content-type" content="text/html; charset=utf-8" /></head>';
$style = '<style type="text/css">.content{text-align: justify} .t800{max-width:600px;} </style>';
foreach($html->find('div[class="postbody"]') as $postbody)
{
$h3 = $postbody->find('h3',0);
echo $h3->plaintext . '<br/>';
$content = $postbody->find('div[class=content]',0);
//echo $content . '<br/>';
$html2 = str_get_html($content);
$img = $html2->find('img[alt!=tablica.png]',0);
$img->outertext = '';
echo $html2->innertext;
// Создаем и пишем в HTML файл
$fp = fopen($path .$i . ".html", "w"); // Открываем файл в режиме записи
fwrite($fp,$header);
fwrite($fp,$style);
fwrite($fp,$html2->innertext);
//Конец записм в HTML файл
$newimg = $content->find('img[alt!=tablica.png]',0);
if ($newimg <> '' & $i < 52)
{
echo '<br/>Новый Имидж<br/>'. $newimg . '<br/>Конец нового имиджа<br/>';
echo '<br/><br/>I =' . $i . '<br/><br/>';
$url_img = $newimg->src;
echo '<br/>ВЫВОДИМ HREF: ' . $url_img;
$img_path = $path . $i . '.jpg';
grab_image($url_img,$img_path);
$img_html = '<br><img class="t800" src="'. $i . '.jpg" width="100%" height="auto" ><br>';
fwrite($fp,$img_html);
}
fclose($fp); //Закрытие файла
$i++;
}
//освобождаем ресурсы
$html->clear();
unset($html);
// Это функция grub_image() че картинки скачивает сurl-ом и сохраняет (взята из комментариев на Stack Overflow)
// ЗЫ сurl-ом потому что curl-ом быстрее скачивается
function grab_image($url,$saveto){
$ch = curl_init ($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_BINARYTRANSFER,1);
$raw=curl_exec($ch);
curl_close ($ch);
if(file_exists($saveto)){
unlink($saveto);
}
$fp = fopen($saveto,'x');
fwrite($fp, $raw);
fclose($fp);
}
?>
Запустил его и через 3 минуты он создал мне в папке hystory 51 файлик html c отдельными ответами, а так же закачал и переменовал и в ставил в эти файлики 51 картинку с новыми именами.
Цитата(t800 @ 01 May 2017, 10:34)
Оказывается чтобы засунуть сайт в приложение надо сделать так чтобы сайт был на чистом HTML и чтобы у каждого ответ лежал в своей HTML файлике 1.html , 2.html и т.д. до 51.html потому что вопросов к экзамену 51
Ну так тогда это просто компилятор html в chm с прикрученным лаунчером.Цитата(hippocamus @ 01 May 2017, 15:29)
Цитата(t800 @ 01 May 2017, 10:34)
Оказывается чтобы засунуть сайт в приложение надо сделать так чтобы сайт был на чистом HTML и чтобы у каждого ответ лежал в своей HTML файлике 1.html , 2.html и т.д. до 51.html потому что вопросов к экзамену 51
Ну так тогда это просто компилятор html в chm с прикрученным лаунчером.chm это файл справки в Windows, в Андроид такого нету.
Цитата(tolich @ 01 May 2017, 19:20)
Ну это же ЧУЖАЯ программа, к тому же еще и без исходников не опенсорс и не GPL. Как я ее выложу на Google Play?
Это было в топе поиска. Тебе нужно, ты ищешь.
Цитата(tolich @ 01 May 2017, 19:41)
Это было в топе поиска. Тебе нужно, ты ищешь.
Но я же хочу сделать свою программу-справочник, зачем мне искать чужую?
Фух! Наконец-то получилось!
Вот опубликовал приложение-справочник со всеми ответами см. https://play.google.com/store/apps/details?...ev.t800.history
Вот опубликовал приложение-справочник со всеми ответами см. https://play.google.com/store/apps/details?...ev.t800.history
Кстати, оказывается ученые очень сильно заботятся о ссылках и на ихние статья если кто-нибудь использует их фото или пишет что они что-то сказали. Потому что я когда брал картинки с разных сайтов для программы-справочника, то я как это требует Google послал на сайты письмо с вопросом что не возражают ли они что я вставляю ихние фото в свой справочник и что если они возражают то я их удалю.
И мне никто не ответил кроме ученых-антропологов, которые сказали что не возражают, но только если я добавлю в свою программу-справочник
активную ссылку на страничку с их статьями. Ну я конечно же добавил, Вот так:

И мне никто не ответил кроме ученых-антропологов, которые сказали что не возражают, но только если я добавлю в свою программу-справочник
активную ссылку на страничку с их статьями. Ну я конечно же добавил, Вот так:
Цитата
Потому что я когда брал картинки с разных сайтов для программы-справочника, то я как это требует Google послал на сайты письмо с вопросом что не возражают ли они что я вставляю ихние фото в свой справочник и что если они возражают то я их удалю.
Хочешь, секрет расскажу? Всем похеру, даже законопослушным американцам

Ну, ты и сам это понял, наверное)
Цитата
И мне никто не ответил
Цитата(Эроласт @ 08 May 2017, 13:57)
Цитата
Потому что я когда брал картинки с разных сайтов для программы-справочника, то я как это требует Google послал на сайты письмо с вопросом что не возражают ли они что я вставляю ихние фото в свой справочник и что если они возражают то я их удалю.
Хочешь, секрет расскажу? Всем похеру, даже законопослушным американцам

Всем кроме ученых-анропологов

 - они то разрешили чтоб их картинки были в справочнике только если я ссылку на страницу с их статьями сделаю и так чтобы она обязательно открывалась если на нее нажать
- они то разрешили чтоб их картинки были в справочнике только если я ссылку на страницу с их статьями сделаю и так чтобы она обязательно открывалась если на нее нажать  , и поэтому мне пришлось вчера разбираться как это сделать чтоб из справочника внешний браузер вызывался.
, и поэтому мне пришлось вчера разбираться как это сделать чтоб из справочника внешний браузер вызывался.ЗЫ И кстати, вот ихнее фото в программе-справочнике в примечании к одному из ответов:

(а всего от них я вроде картинок пять-шесть в справочник вставил)
Кстати антропологи мне написали, что не против если я сделаю какое-нибудь приложение-словарик про всякие черепа что они копают, только там надо обязательно с поиском делать, а не так как в шпаргалке где вопросы просто пролистывать надо. Вот сейчас решил посмотреть как на java делать поиск.
t800, открой уже свой блог в http://forum.df2.ru/index.php?showforum=138 и пиши там всякую хрень)
Цитата(Эроласт @ 13 May 2017, 20:11)
t800, открой уже свой блог в http://forum.df2.ru/index.php?showforum=138 и пиши там всякую хрень)
А зачем блог? Просто я решил теперь попробовать сделать умный справочник и чтобы был с настоящим поиском , а на своем справочнике пробовать боюсь потомучто его в шклое все скачали и поставили. Поэтому и решил попробовать сделать поиск на справочнике про черепа, потому что если не получится никто ругаться не будет.
Цитата(t800 @ 13 May 2017, 17:56)
потомучто его в шклое все скачали и поставили.
И что? А как по-твоему люди вообще обновляют программы? Цитата(ivyl @ 14 May 2017, 15:20)
Цитата(t800 @ 13 May 2017, 17:56)
потомучто его в шклое все скачали и поставили.
И что? А как по-твоему люди вообще обновляют программы? Наверное так же как я обновляю через Google Developer Console. Просто экзамен ведь через неделю. А программу-шапаргалку поставили все одноклассники и еще из других классов тоже поставили. Если я сейчас что-нибудь не так сделаю так, что программа вдруг перестанет работать - на меня ругаться же все будут, поэтому я ее трогать вообще не хочу пока экзамен все не сдадут.
Цитата(t800 @ 14 May 2017, 20:01)
Наверное так же как я обновляю через Google Developer Console. Просто экзамен ведь через неделю. А программу-шапаргалку поставили все одноклассники и еще из других классов тоже поставили. Если я сейчас что-нибудь не так сделаю так, что программа вдруг перестанет работать - на меня ругаться же все будут, поэтому я ее трогать вообще не хочу пока экзамен все не сдадут.
Перед тем, как что-то выкатывать в маркет, можно протестировать другую сборку на своем устройстве, либо через эмулятор.
Цитата(SaintDark @ 15 May 2017, 03:36)
Цитата(t800 @ 14 May 2017, 20:01)
Наверное так же как я обновляю через Google Developer Console. Просто экзамен ведь через неделю. А программу-шапаргалку поставили все одноклассники и еще из других классов тоже поставили. Если я сейчас что-нибудь не так сделаю так, что программа вдруг перестанет работать - на меня ругаться же все будут, поэтому я ее трогать вообще не хочу пока экзамен все не сдадут.
Перед тем, как что-то выкатывать в маркет, можно протестировать другую сборку на своем устройстве, либо через эмулятор.
Ну это то все время делаешь (в эмуляторе), но почему-то получается что в эмуляторе вроде все нормально, а выложишь на Google Play
а приложение почему-то не работает и приходится по десять раз еще потом исправлять.
Так ну вроде получилось сделать поиск
См. https://play.google.com/store/apps/details?...800.volcabulary
ЗЫ Если кому интересно могу рассказать как делается
См. https://play.google.com/store/apps/details?...800.volcabulary
ЗЫ Если кому интересно могу рассказать как делается
Всё! Сделал последнюю версию приложения Справочник-Шпаргалка - 1.00.65,
Теперь с чтением ответов ГОЛОСОМ
(Последняя версия поэтому, что до экзамена осталось только три дня)
И по этому случаю я написал подробную инструкцию по установке программы, чтобы можно было ответы слушать, а не читать!
1. Сначала устанавливаем само приложение "Ответы по Истории Казахстана" (если приложение установлено, этот пункт пропускаем).
https://play.google.com/store/apps/details?...ev.t800.history
2. Потом устанавливаем программу "RHVoice (T-800 Mod)".
https://play.google.com/store/apps/details?...rhvoice.android
3. Теперь ставим пакеты, которые нужны для воспроизведения синтеза речи:
* RHVoice (T-800 Mod) - Русский
https://play.google.com/store/apps/details?...anguage.russian
* Голос A - RHVoice (T-800 Mod) [или Голос B - RHVoice (T-800 Mod)]
https://play.google.com/store/apps/details?...roid.voice.anna
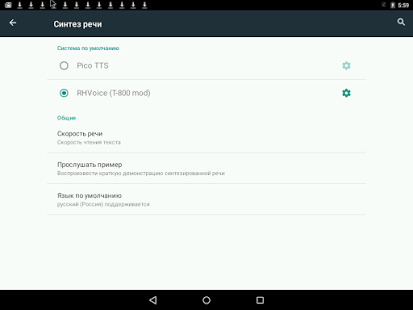
4. Потом заходим в настройки планшета. В графе "Личные данные" ищем строку "Язык и ввод". Там ищем графу "Голосовой ввод", и жмём на строку "Синтез речи". И в графе "Система по умолчанию" ставим галочку возле "RHVoice (T-800 Mod)".
5. Потом закрываем программу "Ответы по Истории Казахстана" (если она была запущена), открываем её снова, выбираем любой вопрос, и кликаем по кнопке "Прочитать вслух".
ВСЁ!
Теперь с чтением ответов ГОЛОСОМ
(Последняя версия поэтому, что до экзамена осталось только три дня)
И по этому случаю я написал подробную инструкцию по установке программы, чтобы можно было ответы слушать, а не читать!
1. Сначала устанавливаем само приложение "Ответы по Истории Казахстана" (если приложение установлено, этот пункт пропускаем).
https://play.google.com/store/apps/details?...ev.t800.history
2. Потом устанавливаем программу "RHVoice (T-800 Mod)".
https://play.google.com/store/apps/details?...rhvoice.android
3. Теперь ставим пакеты, которые нужны для воспроизведения синтеза речи:
* RHVoice (T-800 Mod) - Русский
https://play.google.com/store/apps/details?...anguage.russian
* Голос A - RHVoice (T-800 Mod) [или Голос B - RHVoice (T-800 Mod)]
https://play.google.com/store/apps/details?...roid.voice.anna
4. Потом заходим в настройки планшета. В графе "Личные данные" ищем строку "Язык и ввод". Там ищем графу "Голосовой ввод", и жмём на строку "Синтез речи". И в графе "Система по умолчанию" ставим галочку возле "RHVoice (T-800 Mod)".
5. Потом закрываем программу "Ответы по Истории Казахстана" (если она была запущена), открываем её снова, выбираем любой вопрос, и кликаем по кнопке "Прочитать вслух".
ВСЁ!
Для просмотра полной версии этой страницы, пожалуйста, пройдите по ссылке.